自动补全:
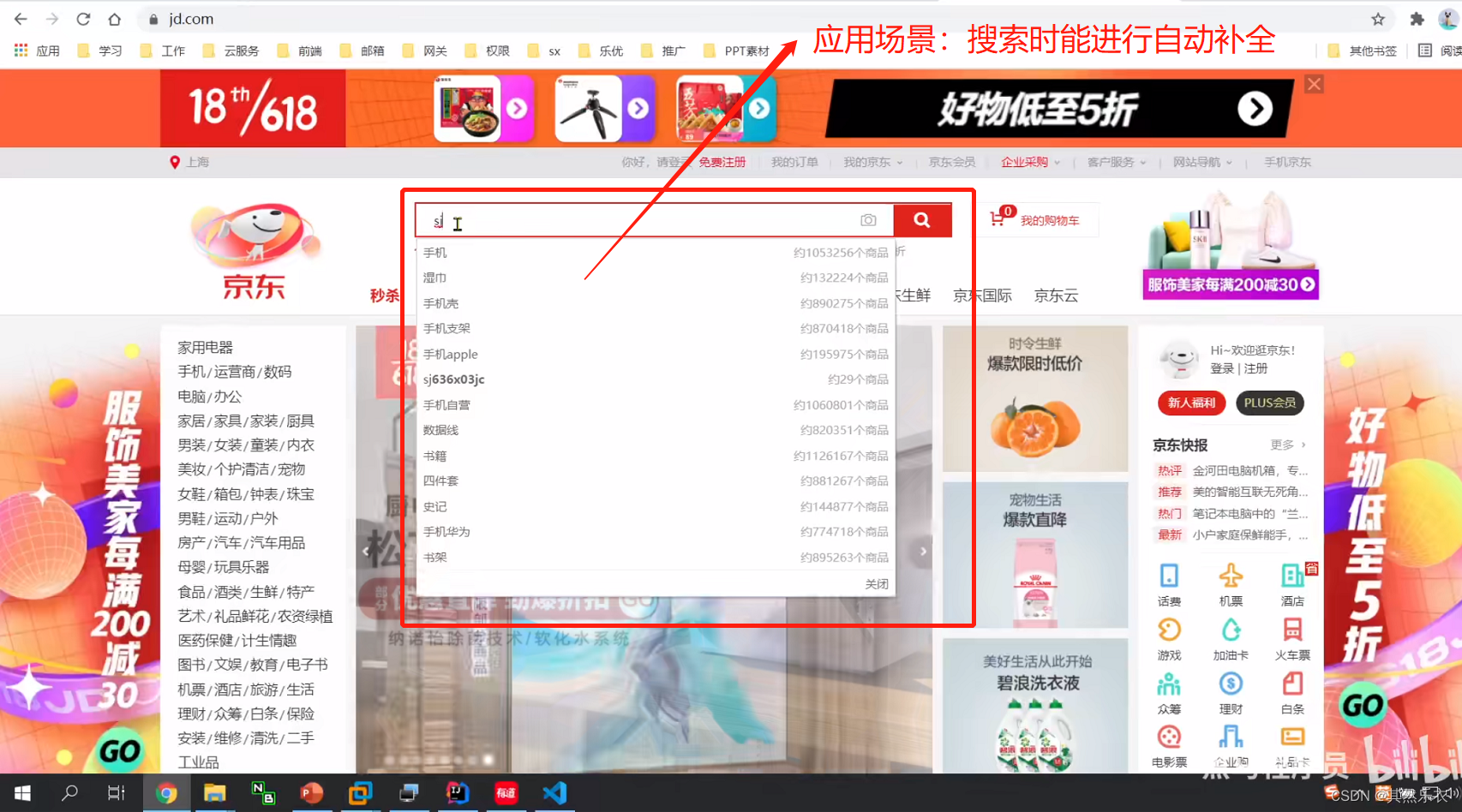
要实现根据字母做补全,就必须对文档按照拼音分词。在GitHub上恰好有elasticsearch的拼音分词插件。地址:GitHub - medcl/elasticsearch-analysis-pinyin: This Pinyin Analysis plugin is used to do conversion between Chinese characters and Pinyin.
用初始化的拼音分词器进行分词:

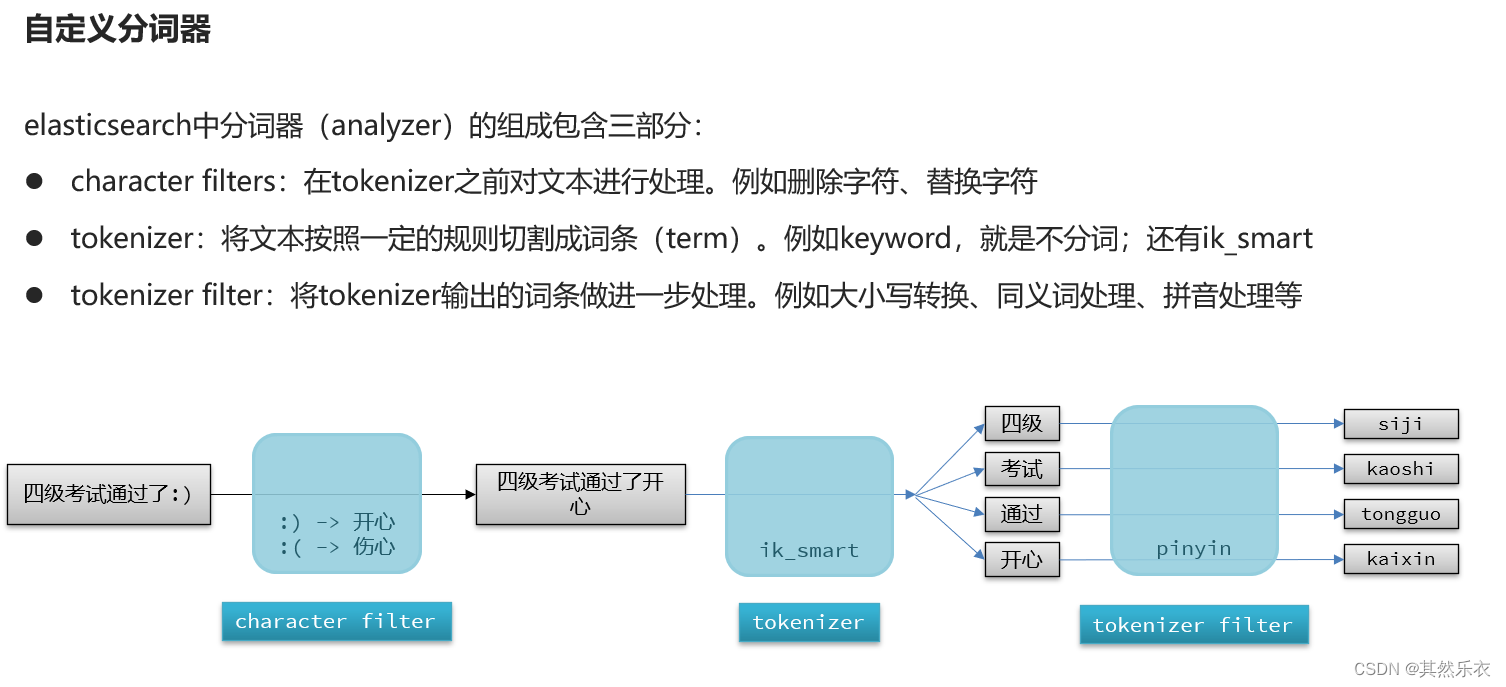
为了实现得到的分词有中文也有拼音,我门需要
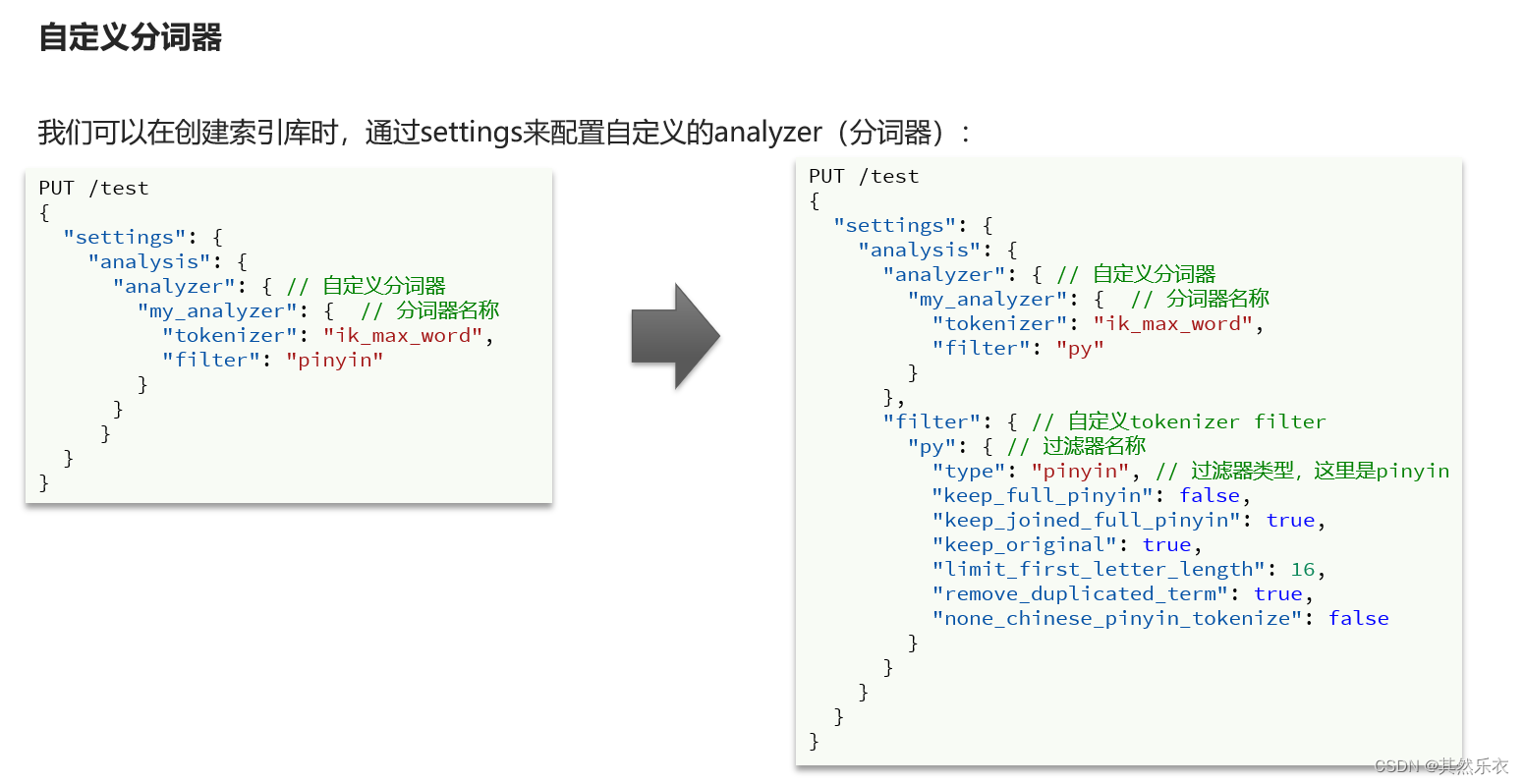
自定义拼音分词器(中文 + 拼音)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| // 自定义拼音分词器
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "my_analyzer"
}
}
}
}
|
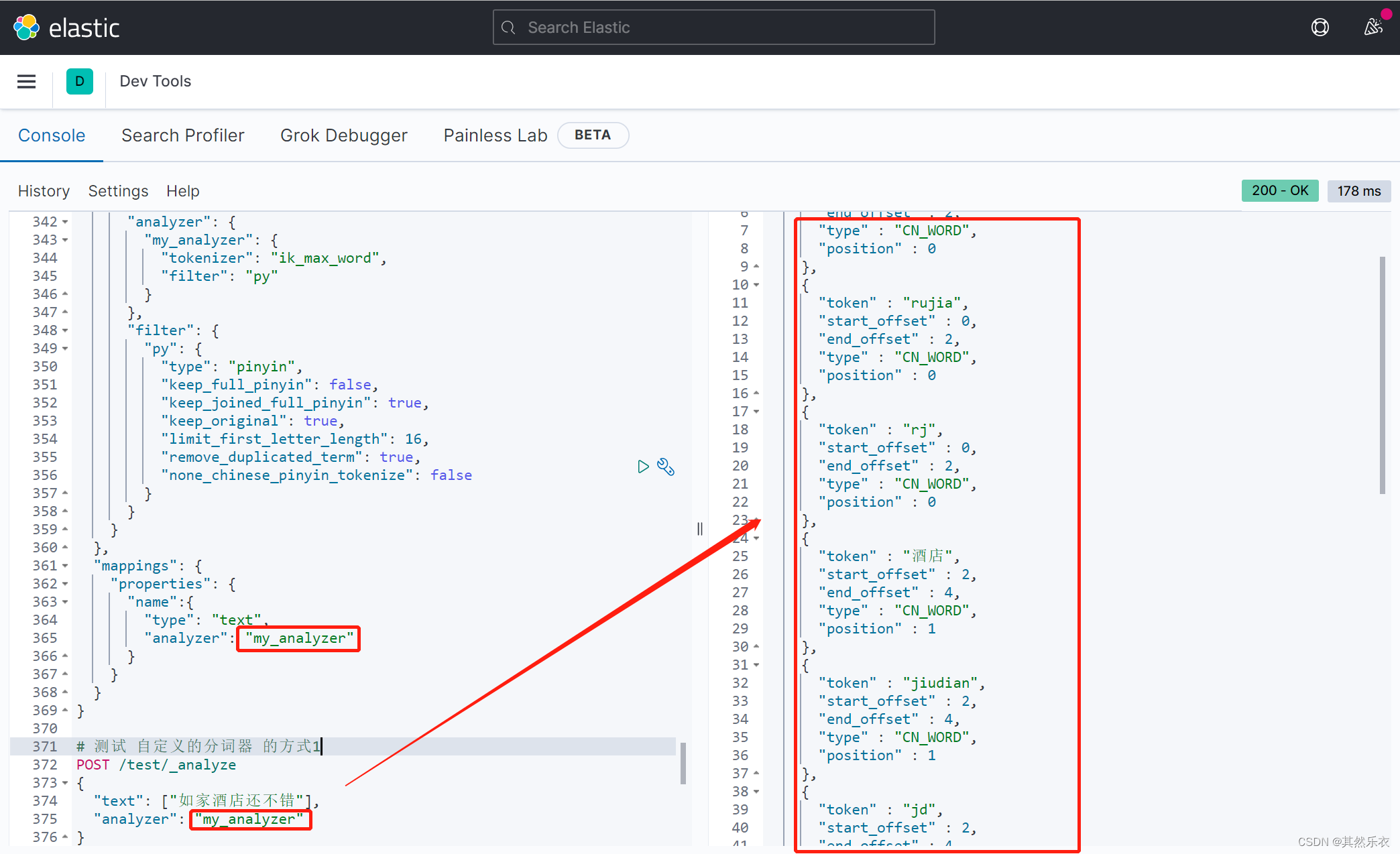
测试方式1:
1
2
3
4
5
6
| # 测试 自定义的分词器 的方式1
POST /test/_analyze
{
"text": ["如家酒店还不错"],
"analyzer": "my_analyzer"
}
|
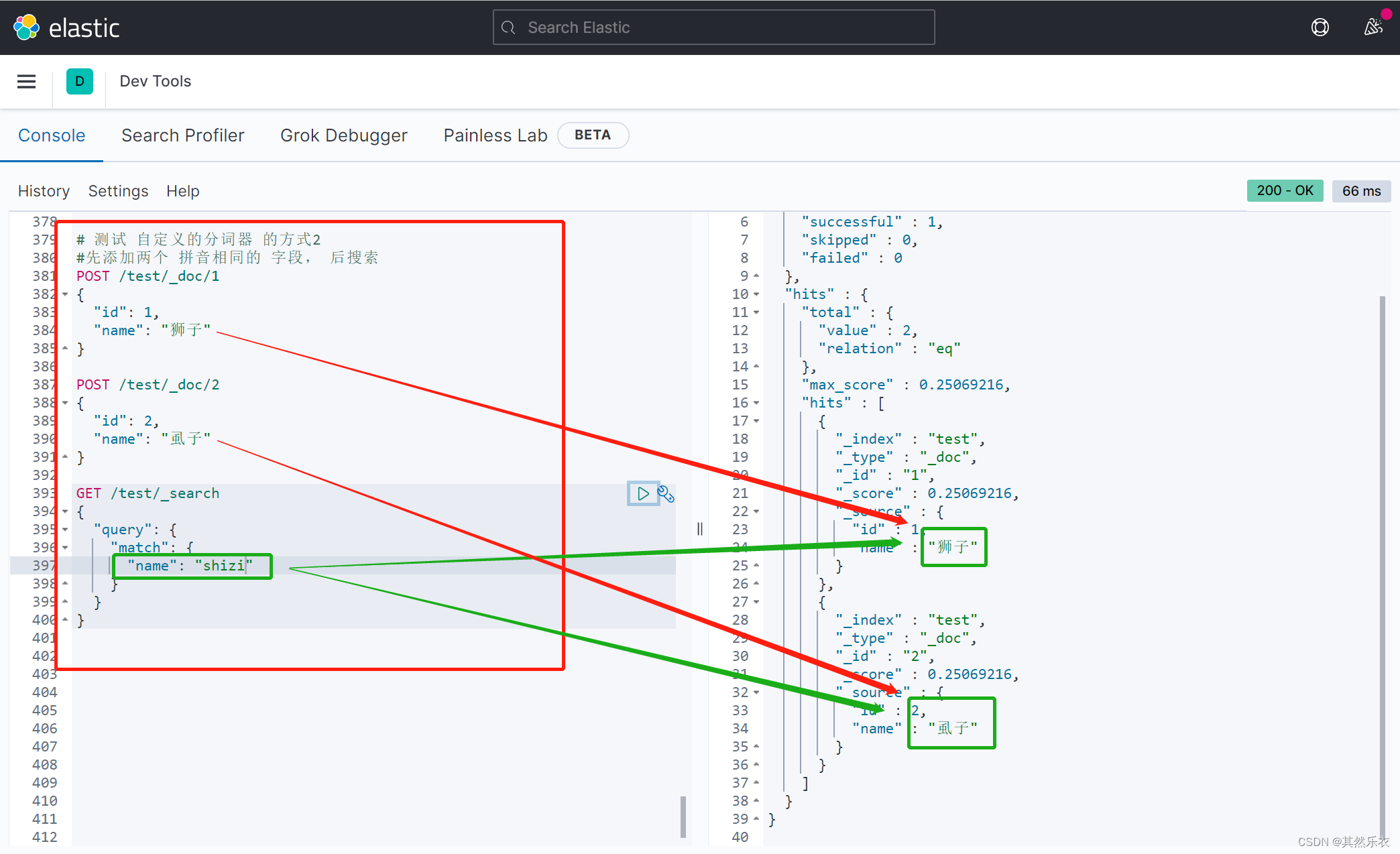
测试 自定义的分词器 的方式2: 先添加两个 拼音相同的 字段, 后搜索
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| # 测试 自定义的分词器 的方式2
#先添加两个 拼音相同的 字段, 后搜索
POST /test/_doc/1
{
"id": 1,
"name": "狮子"
}
POST /test/_doc/2
{
"id": 2,
"name": "虱子"
}
GET /test/_search
{
"query": {
"match": {
"name": "shizi"
}
}
}
|
注意事项:
问题:当我用自定义的拼音分词器去搜索一段又狮子的中文时,却也搜出了库里面的的虱子,因为“狮子”和“虱子”有着相同的拼音,而拼音分词器就是可以将相同拼音的中文都搜出来
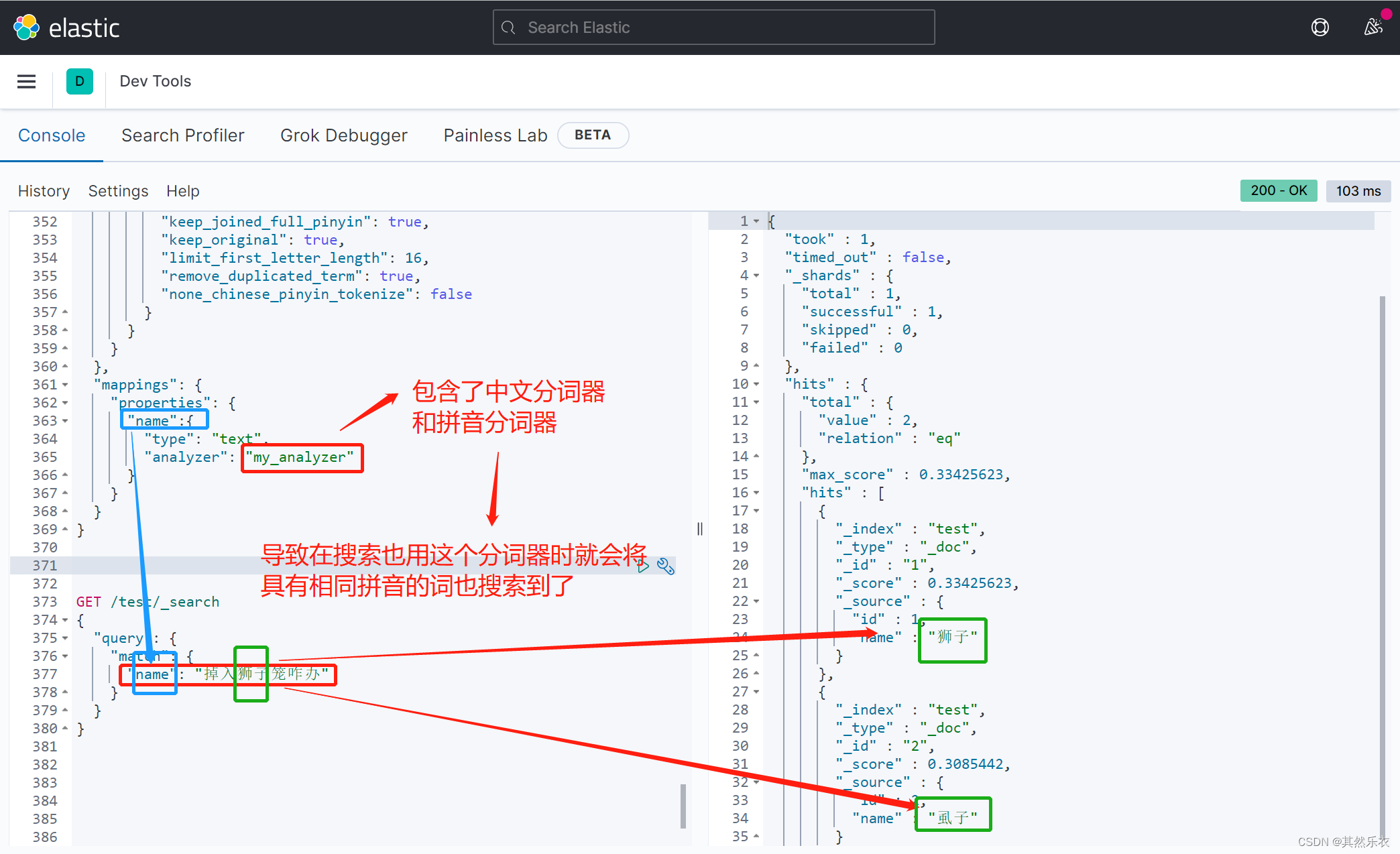
解决:
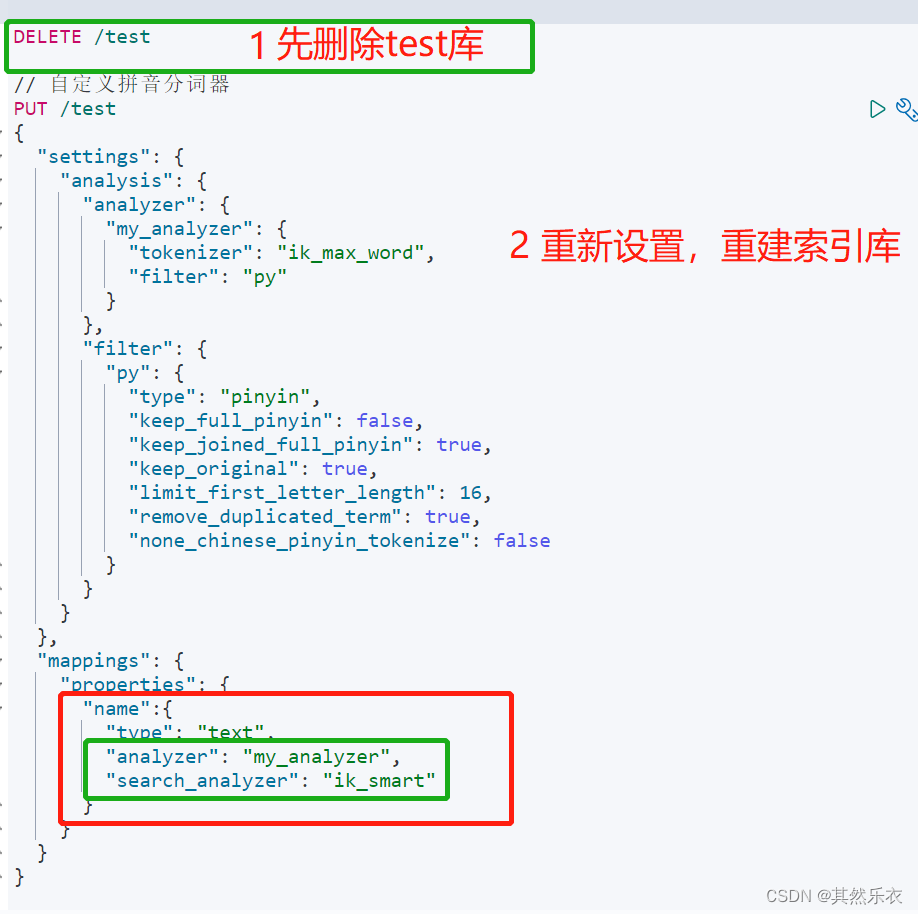
为了避免搜索到同拼音字,搜索时不要用拼音分词器

删库,重设置和重建索引库,再重新测试上面的测试方式2就可以了
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| //删除库
DELETE /test
// 自定义拼音分词器
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "my_analyzer",
"search_analyzer": "ik_smart"
}
}
}
}
|
测试(和上面的测试方式2一样):
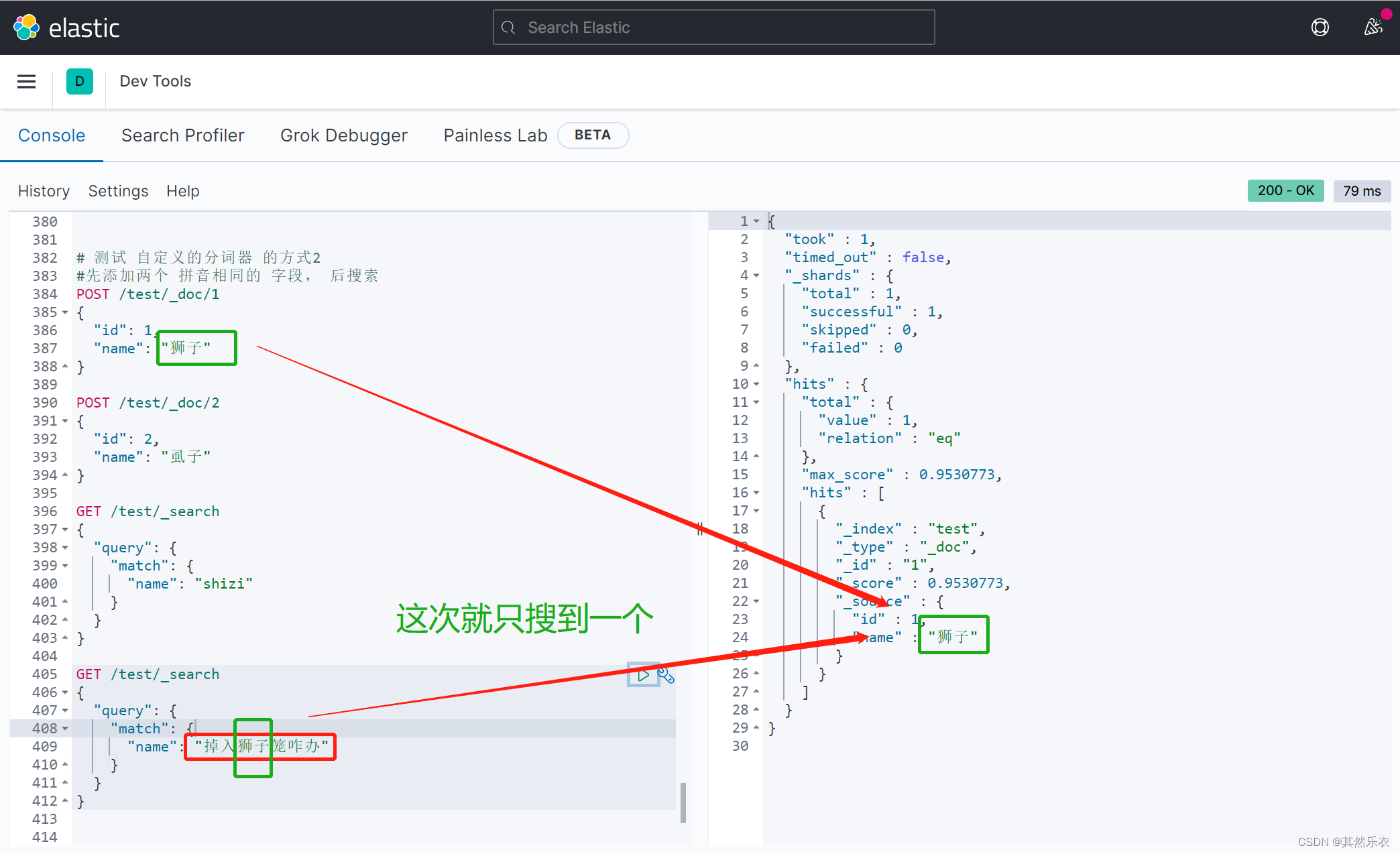
总结:

DSL实现自动补全查询:
(45条消息) DSL实现自动补全查询_其然乐衣的博客-CSDN博客
