
- pom.xml配置之springboot
1.1 继承springboot父项目依赖
1 | <parent> |
1.2 插件依赖
1 | <dependencies> |
- 启动类配置
1 | @SpringBootApplication |
- application.yml
1 | <parent> |
1.2 插件依赖
1 | <dependencies> |
1 | @SpringBootApplication |
(本博文的方法对于阿里云和腾讯与服务器都适用 )
场景:
部署一个后端程序(climate-0.0.1-SNAPSHOT.jar)到我腾讯云的服务器上,常规启动命令如下:
1 | java -jar climate-0.0.1-SNAPSHOT.jar |
上图表示项目部署成功,便可以在浏览器上进行访问
但是关闭终端后,就不能访问了,也就达不到上线的效果。
而我们想项目程序在关闭退出终端后,也一样继续运行,
这时候需要使用 nohup 命令启动(该命令可以在你退出帐户/关闭终端之后继续运行相应的进程)
输入如下命令:
1 | nohup java -jar climate-0.0.1-SNAPSHOT.jar |
但是会报错(表示:执行nohup命令的时候,经常会没有写入权限的错误)
1、原因
是因为使用 nohup 会产生日志文件,默认写入到 nohup.out
2、解决
将 nohup 的日志输出到 /dev/null,这个目录会让所有到它这的信息自动消失
1 | nohup java -jar climate-0.0.1-SNAPSHOT.jar > /dev/null 2> /dev/null & |
其它解决方法:
就是在末尾直接加一个&就就能够直接在后台运行
1 | nohup java -jar climate-0.0.1-SNAPSHOT.jar & |
停止进程
如果想停止进程运行的话,可通过命令(kill -9 进程号PID)进程号来杀死
另外也可以使用 ps -def | grep “进程名” 命令来查找PID。
找到 PID 后,就可以使用 kill PID 来删除。
1 | kill -9 进程号PID |
如果发现启动时,查看日志发现端口号被占了
用 lsof -i:[端口号] 查看使用某端口的进程
1 | lsof -i:[端口号] |
然后使用kill杀掉进城后再启动
终止后台运行的进程
1 | kill -9 进程号PID |
比如:发现 6868 端口被占用了

问题描述
MyBatis无法查询出属性名和数据库字段名不完全相同的数据。
即:属性名和数据库字段名分别为驼峰命名和下划线命名时查出的数据为NULL。
问题分析
MyBatis默认是属性名和数据库字段名一一对应的,即
数据库表列:user_name
实体类属性:user_name
但是java中一般使用驼峰命名
数据库表列:user_name
实体类属性:userName
实体类属性:userName
解决方案 (开启驼峰命名转换)
在Spring Boot中,可以通过设置map-underscore-to-camel-case属性为true来开启驼峰功能。
MyBatis配置:
application.properties中:
1 | mybatis.configuration.map-underscore-to-camel-case=true |
application.yml中:
1 | mybatis: |
关联:
pom.xml配置注入依赖:
1 | <!-- mybatisplus+数据库相关开始--> |
1 | spring: |
代码:
1 | import lombok.extern.slf4j.Slf4j; |
代码:
1 | import lombok.extern.slf4j.Slf4j; |
测试:
(给交换机添加绑定关系,这一步看情况做,如果绑定关系已经有的了的表不需要这一步)
测试错误例子
4.总结
SpringAMQP中处理消息确认的几种情况:
publisher-comfirm:
• 消息成功发送到exchange,返回ack
• 消息发送失败,没有到达交换机,返回nack
• 消息发送过程中出现异常,没有收到回执
消息成功发送到exchange,但没有路由到queue,调用ReturnCallback
MQ默认的是内存存储,如果mq发生了宕机,数据是可能丢失。如果要想数据安全,就要做到持久化,也就是能将数据写进磁盘里
交换机和队列持久化
1 | package cn.itcast.mq.config; |
交换机、队列持久了,但并不代表消息就能持久了,所以必须做消息持久化
1 | // 1.准备消息 MessageDeliveryMode.PERSISTENT 消息持久化,这样重启mq消息也可以保留 |
交换机 和 队列 创建 以及 发送消息 的源码其实默认的就是 持久化 的
而之所以学,是因为我们有时候为了提高性能,便可以将一些非必要的设置为 非持久化
测试 auto:
进入simple.queue生产一条消息
填写 消息并发送
刷新
当消费者出现异常后,消息会不断requeue(重新入队)到队列,再重新发送给消费者,然后再次异常,再次requeue,无限循环,导致mq的消息处理飙升,带来不必要的压力:
auto模式 这种情况下,虽然也不好,mq一直在尝试,但是至少消息不会丢失,
auto的这种遇到处理失败后一直投递再投递,这种处理方式不太友好,但是可以改的,看四、失败重试机制
重试次数耗尽之后,其实会返回一个reject拒绝,然后就会把消息丢弃,这是重试机制的默认策略
重试次数耗尽之后,会把消息丢弃,事实上丢弃也没事,因为已经重试了那么多次了,还是失败的,即便把消息再丢回给mq,mq再投递给你,也还是会失败。
那么除了丢弃,还有没有其它的策略呢?有的…
这种方案是最健康的方案了,也建议在生产环境下 使用这种方案
1 | package cn.itcast.mq.config; |
1 | npm i hexo-renderer-marked |

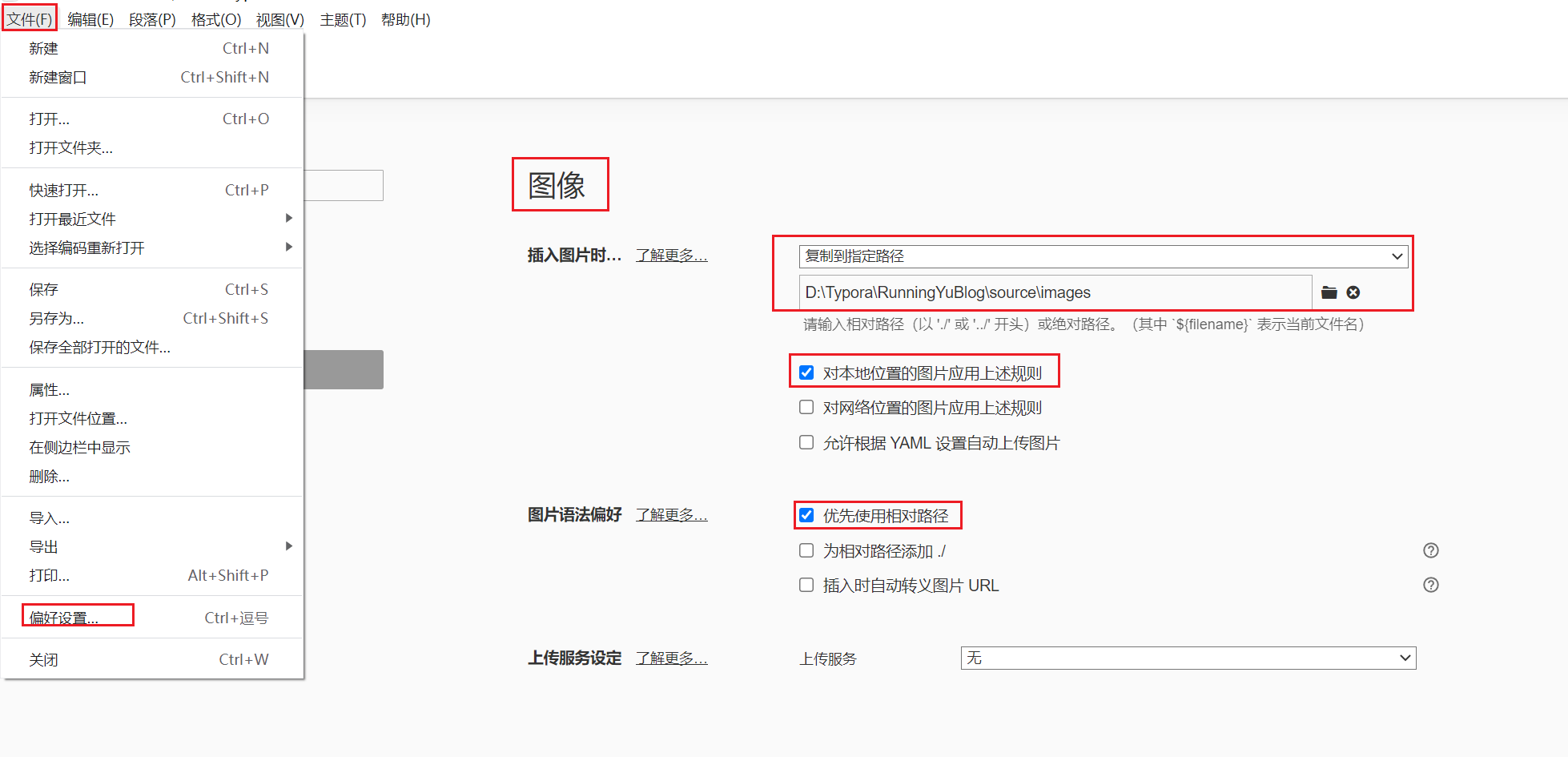
修改你博客的配置文件**_config.yml**
修改配置: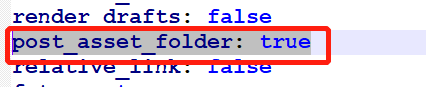
添加上下面语句: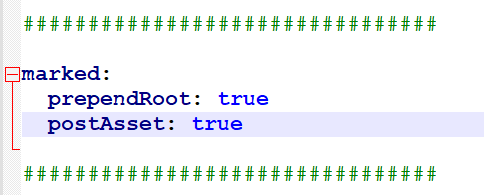
1 | marked: |
之后,你每次复制图片过来,图片路径就是相对路径了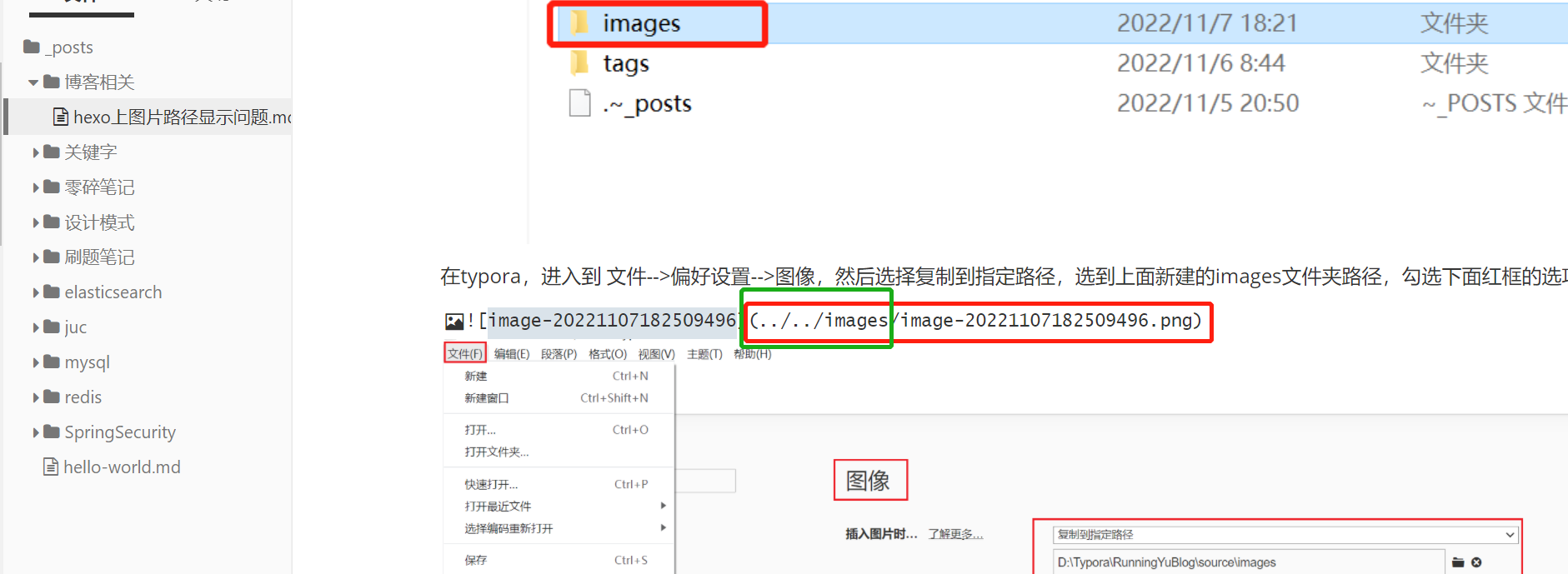
当然,对于网络位置的图片回自动是网络上的图片链接,这种图片在博客上是完全没问题的,比如:
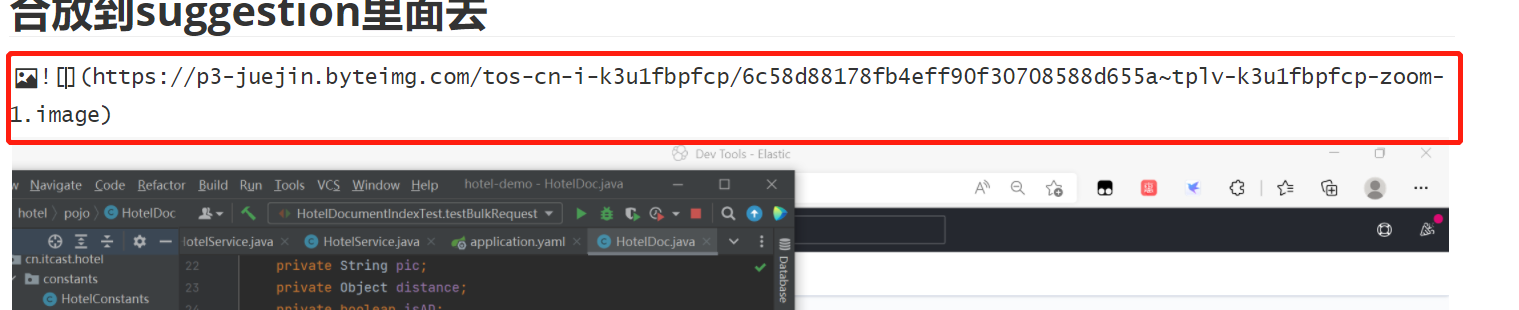
概念对比
实例:
1 | #创建索引库 |
ps:索引库创建好后
理论上是可以进行修改的
但是实际开发中,是**禁止去修改**原有的字段的(**但可以添加新的字段**),因为修改会**对性能的影响是很大**的,可能会导致整个库都不可用
(实例)代码:
1 | # 查询 |
1.引入es的RestHighLevelClient依赖:
1 | <!--elasticsearch--> |
2.因为SpringBoot默认的ES版本是7.6.2,所以我们需要覆盖默认的ES版本:
3.初始化RestHighLevelClient:
1 | return new RestHighLevelClient(RestClient.builder( |
代码:
1 | @Autowired |
其中:
@Autowired
private RestHighLevelClient client;
要在项目启动方法里面注入到bean里
开始时,输入x,不能自动补全
RestAPI实现自动补全:
1 | @GetMapping("suggestion") |
1 | @Override |
便可以进行自动补全了
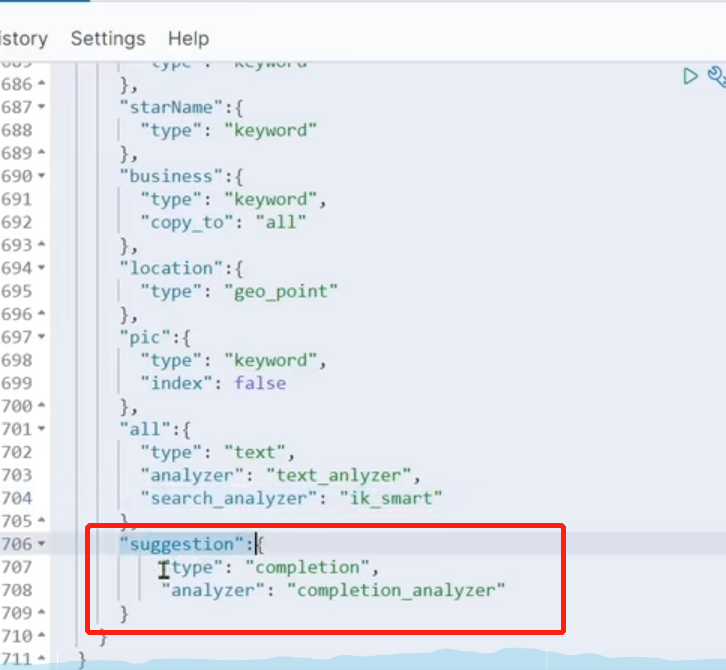
1 | //将brand 和 business 变成集合放到suggestion里 |
切割成功