elasticsearch提供了Completion Suggester查询来实现自动补全功能。这个查询会匹配以用户输入内容开头的词条并返回。为了提高补全查询的效率,对于文档中字段的类型有一些约束:
• 参与补全查询的字段必须是completion类型。
• 字段的内容一般是用来补全的多个词条形成的**数组**。
查询语法如下:
1 | // 自动补全查询 |
测试:
elasticsearch提供了Completion Suggester查询来实现自动补全功能。这个查询会匹配以用户输入内容开头的词条并返回。为了提高补全查询的效率,对于文档中字段的类型有一些约束:
• 参与补全查询的字段必须是completion类型。
• 字段的内容一般是用来补全的多个词条形成的**数组**。
查询语法如下:
1 | // 自动补全查询 |
测试:
要实现根据字母做补全,就必须对文档按照拼音分词。在GitHub上恰好有elasticsearch的拼音分词插件。地址:GitHub - medcl/elasticsearch-analysis-pinyin: This Pinyin Analysis plugin is used to do conversion between Chinese characters and Pinyin.
为了实现得到的分词有中文也有拼音,我门需要
1 | // 自定义拼音分词器 |
1 | # 测试 自定义的分词器 的方式1 |
1 | # 测试 自定义的分词器 的方式2 |
问题:当我用自定义的拼音分词器去搜索一段又狮子的中文时,却也搜出了库里面的的虱子,因为“狮子”和“虱子”有着相同的拼音,而拼音分词器就是可以将相同拼音的中文都搜出来
解决:
为了避免搜索到同拼音字,搜索时不要用拼音分词器
删库,重设置和重建索引库,再重新测试上面的测试方式2就可以了
代码:
1 | //删除库 |
测试(和上面的测试方式2一样):
总结:
在对应的service层里面写:
HotelService里的代码如下:
1 | @Override |
1 | @Test |
ps:
举例:
我们要求获取每个品牌的用户评分的min、max、avg等值.
我们可以利用stats聚合:(stats可以计算min、max、avg等)
1 | # 嵌套聚合metric |



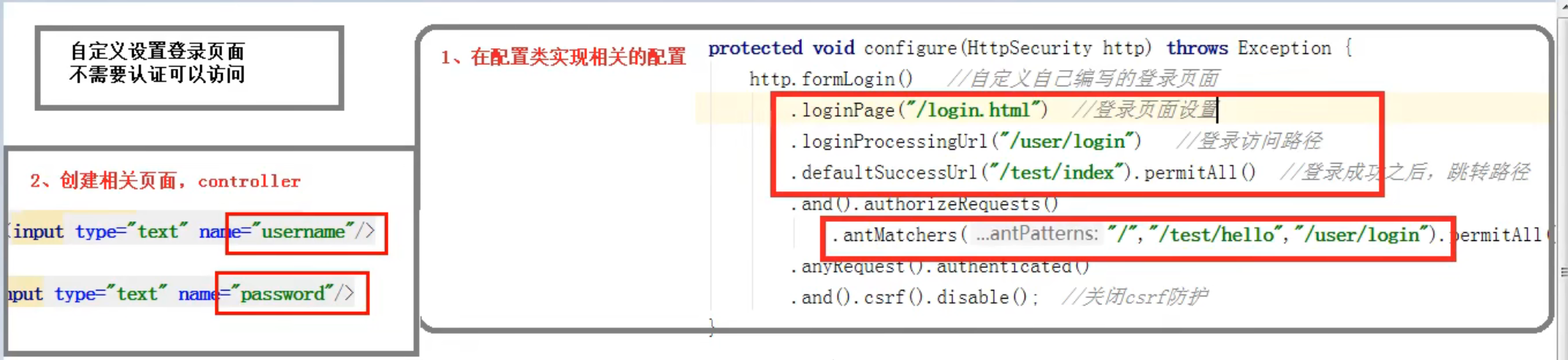
设置登录用户名和密码
properties为例
1 | server.port=8111 |
方式二:通过配置类
1 | import org.springframework.context.annotation.Bean; |
方式三:自定义编写实体类
在验证过程中,它会首先去找你的配置文件、配置类,如果发现其中有用户名和密码,那么它就会去找这个用户名和密码。但如果没有设置,它就会去找一个接口UserDetailsService,到这个接口你可以找通过表单提交或是查数据库或是其它方式设置的密码,然后去验证
到UserDetailsService中找到你返回的用户名和密码和权限
第一步:创建配置类,设置使用哪个userDetailsService实现类
1 | package com.atguigu.springsecurity.config; |
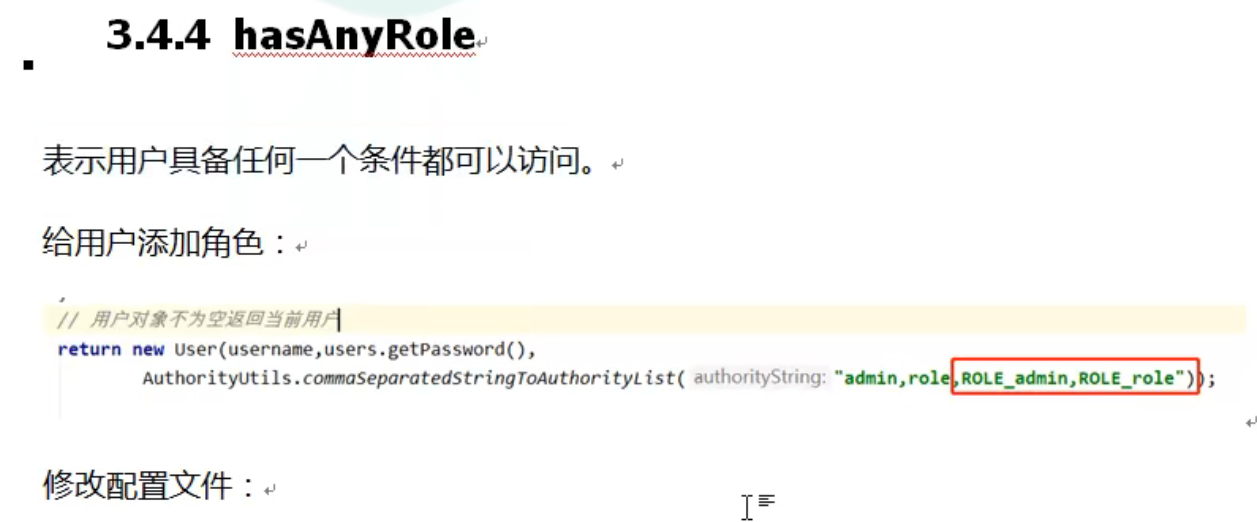
第二步:编写实现类,返回User对象,User对象有用户名、密码和操作权限
1 | package com.atguigu.springsecurity.service; |
引用场景:
一般实际开发中用的比较多的是第三种方式
第一、二种方式:比如要超级管理员的时候,就只能用admin这个用户来登录,这个时候就而已用第一或第二种方式来配置。
第三种方式:主要需求用于查数据库的时候







对应的教程视频:17-尚硅谷-SpringSecurity-web权限方案-自动登录(原理分析)_哔哩哔哩_bilibili
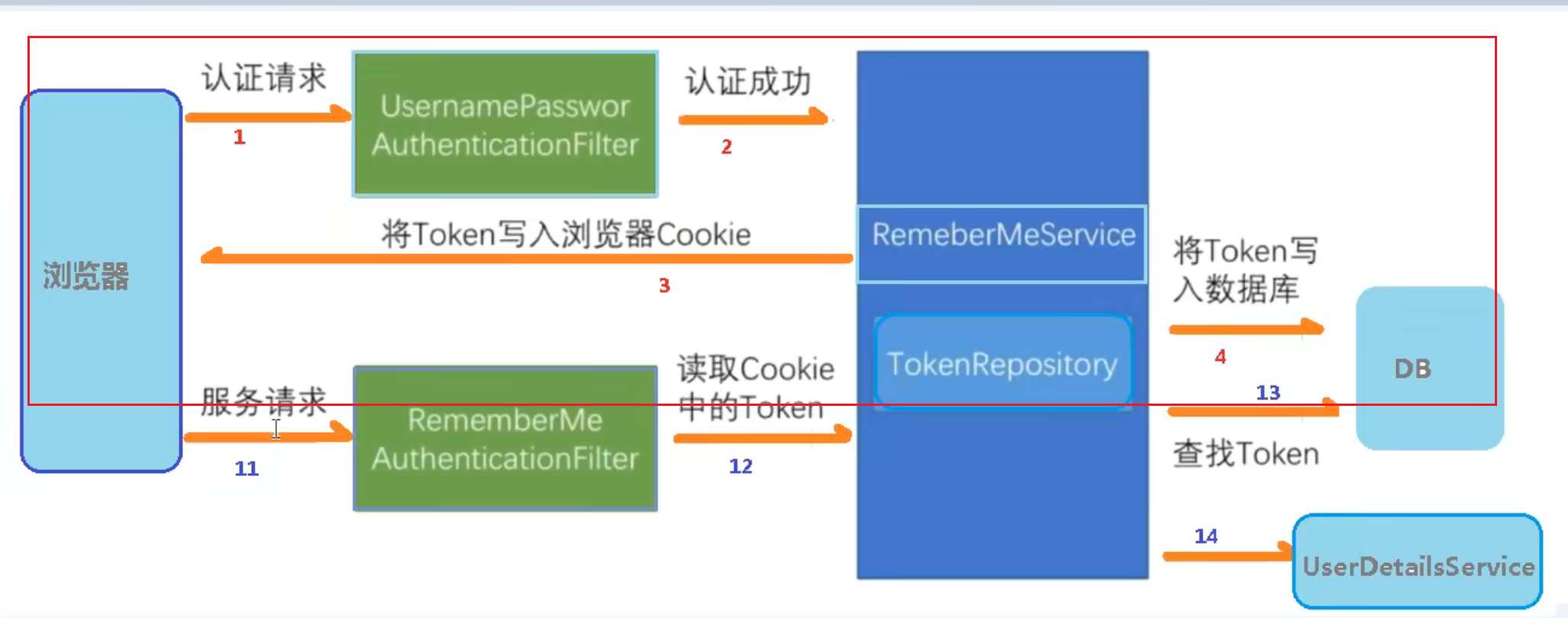
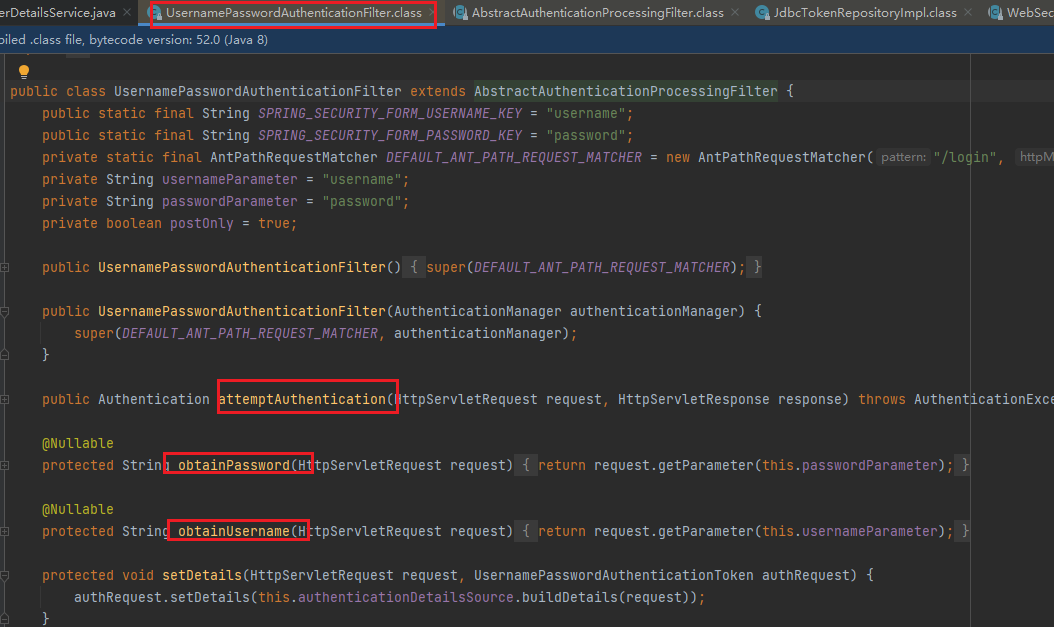
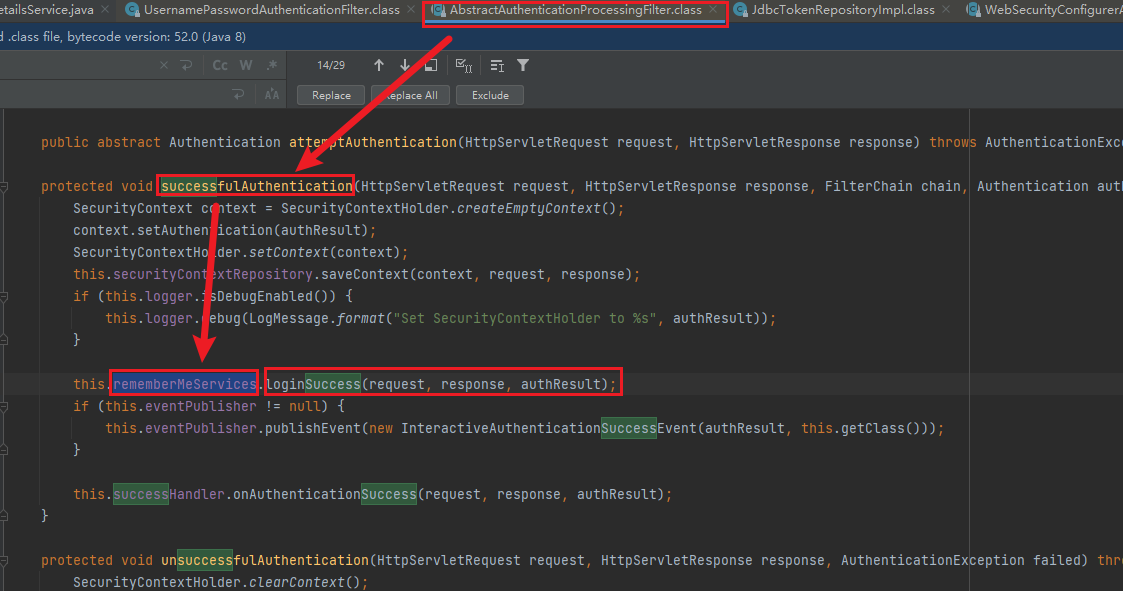
上图红框过程的原理和源码如下:
通过UsernamePasswordAuthenticationFilter来获取用户名和密码,之后验证验证成功后,在调用父类AbsxtractAuthenticationProcessingFilter里的successfulAuthentication方法,然后successfulAuthentication方法里面有RememberMeServices对象,在里面先用TokenRepository生成Token,然后把值放到浏览器Cookies中,并且用JdbcTokenRepositoryImpl里面封装的方法把生成的Token值写到数据库中
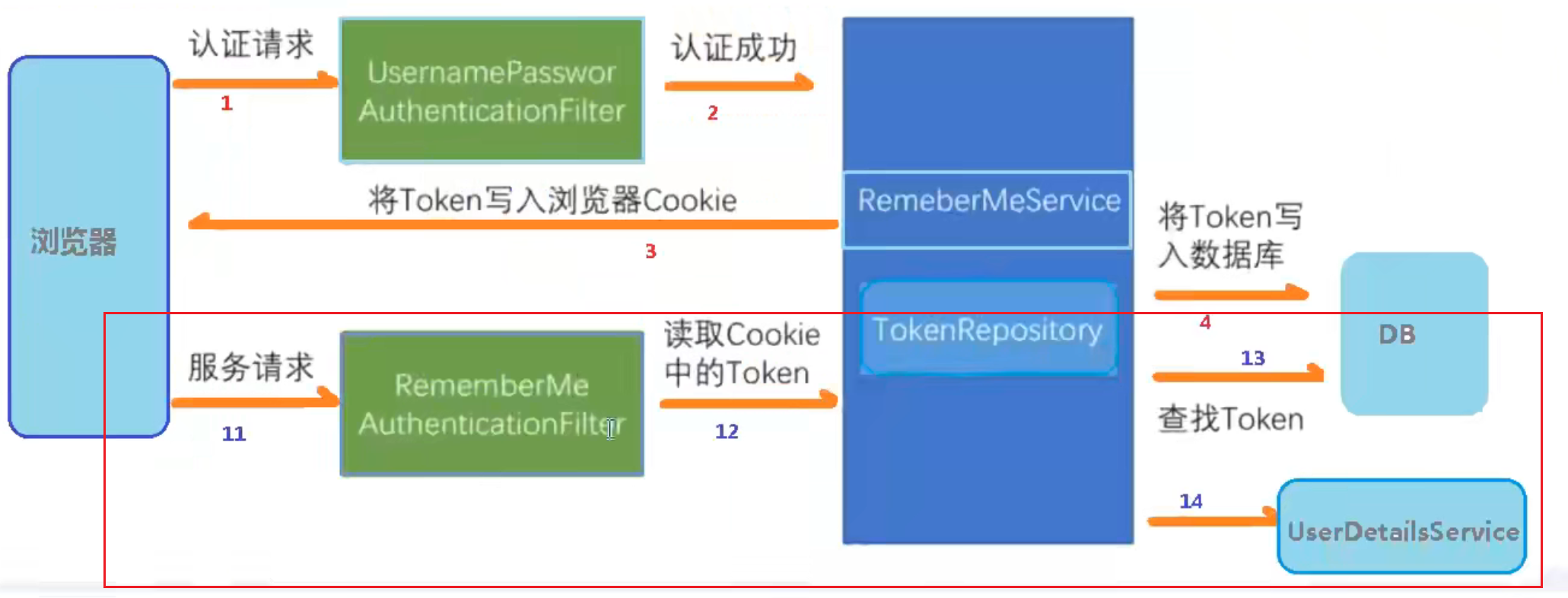
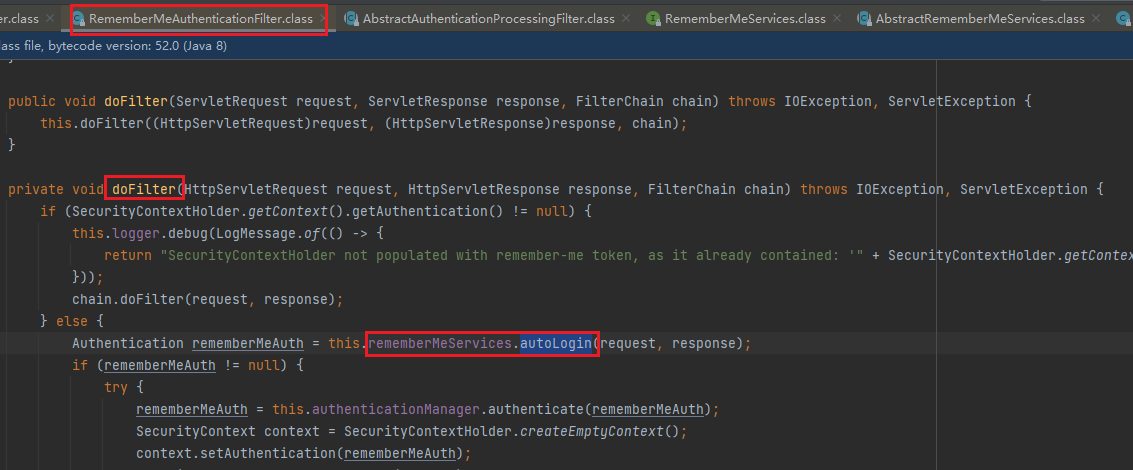
浏览器发送请求,就会调用这个RememberMeAuthenticationFilter过滤器,里面有dofilter里面的RememberMeServices对象的autoLogin方法进行自动登录
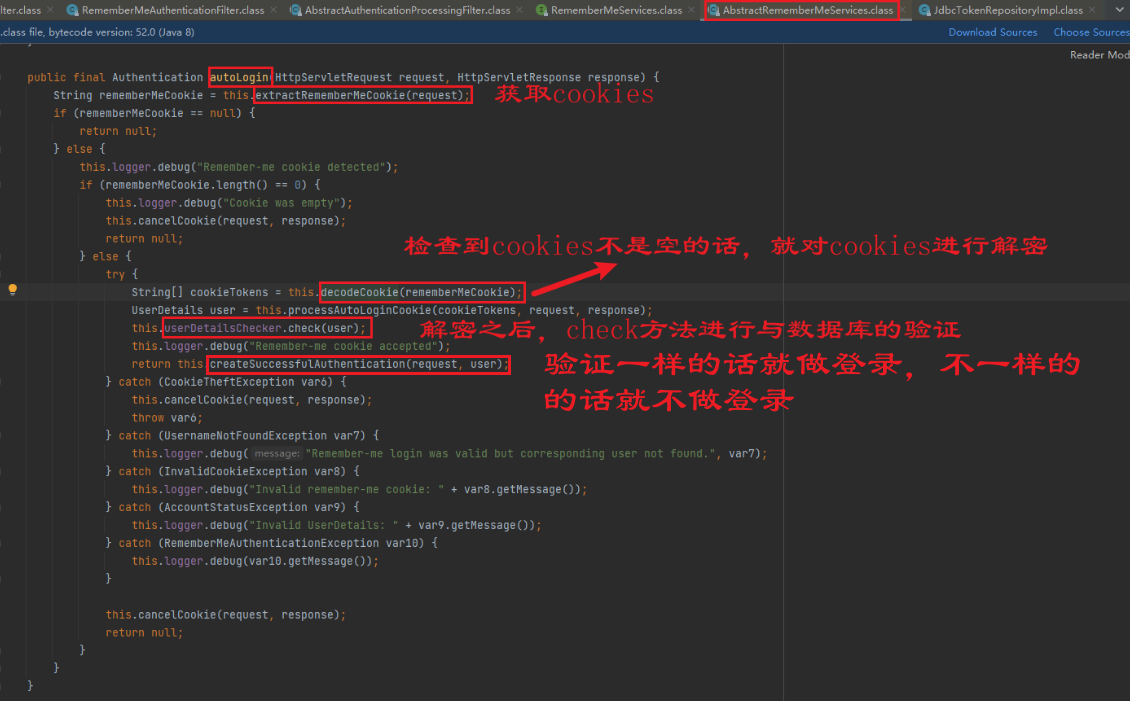
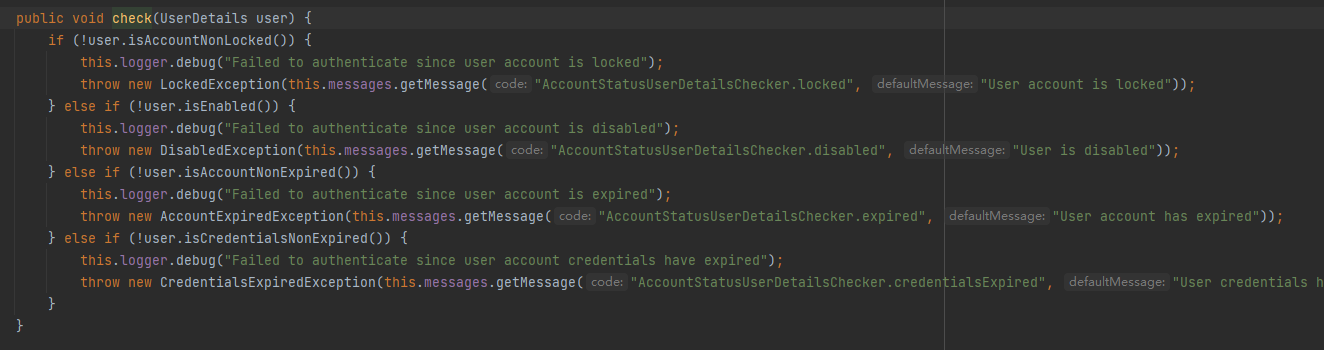
上图check方法的判断过程源码:
对应的教程视频:18-尚硅谷-SpringSecurity-web权限方案-自动登录(功能实现)_哔哩哔哩_bilibili


注意: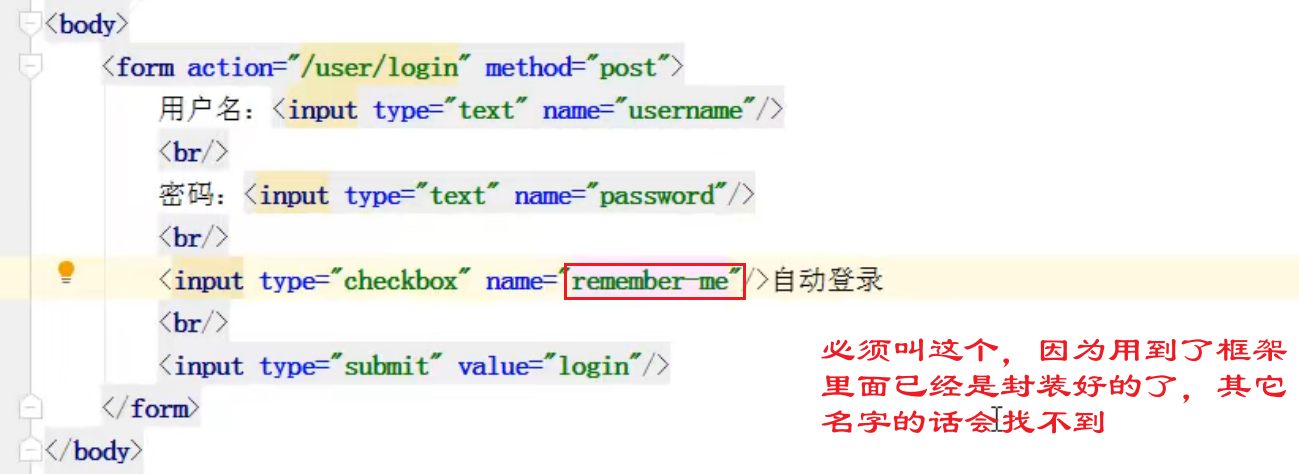
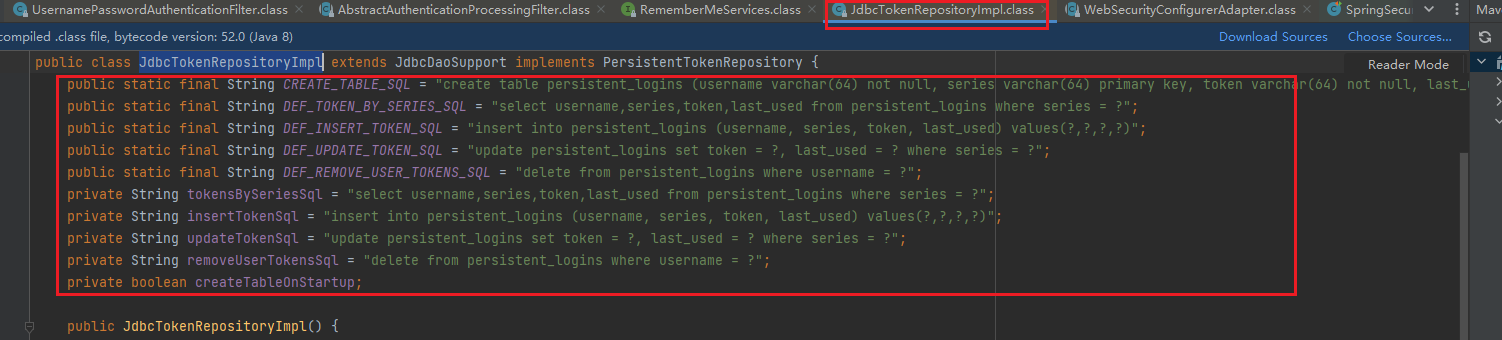
表不一定要我们自己创建,它可以自动我们生成,但是为了看得方便,所以自己可以创建一下,建表语句它里面有提供,可以自己去源码里面复制出来即可,如下:
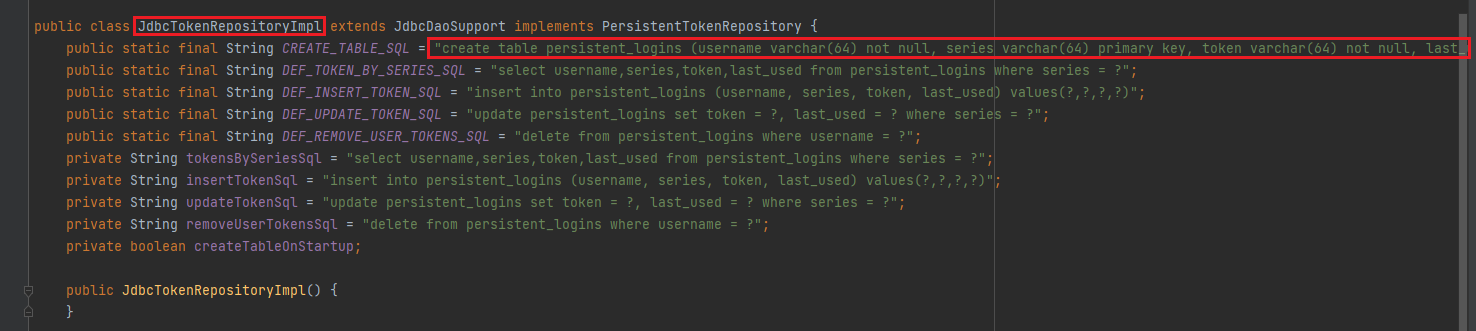
1 | create table persistent_logins ( |
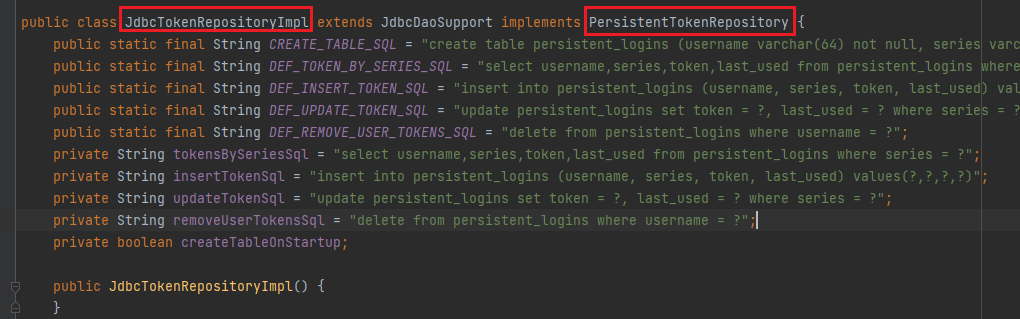
代码:
1 | // 注入数据源 |
CSRF的详解:Web漏洞之CSRF(跨站请求伪造漏洞)详解 - 知乎 (zhihu.com)

在源码中的过程:就是验证之后,生成csrfToken,token存在session里面,每次携带token进行请求,然后拿着csrfToken跟session中的内容作比较,如果它们相同就可以访问,不相同就不能访问。主要代码就是在CsrfFilter里面:
在配置类中如果添加下面这个语句就是关闭CSRF保护,不加上的话,springsecurity是默认开启CSRF保护的

直接上代码,解决 "如何让每周四 18:00:00 定时执行任务 ?"类似问题
1 | import java.time.DayOfWeek; |
Duration类专门用于做时间间隔运算的,如Duration.between( 时间1,时间2 ).toMillis()
聚合(aggregations)可以实现对文档数据的统计、分析、运算。聚合常见的有三类:
桶(Bucket)聚合:用来对文档做分组
•TermAggregation:按照文档字段值分组
•Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
我们要统计所有数据中的品牌有几种,此时可以根据品牌的名称做聚合。
类型为term类型,DSL示例:
1 | # 聚合功能 |
默认情况下,Bucket聚合会统计Bucket内的文档数量,记为 _count,并且按照_count降序排序。
我们可以修改结果排序方式:
1 | # 聚合功能,自定义排序规则 |
默认情况下,Bucket聚合是对索引库的所有文档做聚合的(当数据过于庞大时,会严重影响性能),我们可以限定要聚合的文档范围,只要添加query条件即可
1 | # 聚合功能,限定聚合范围 |
Spring之RestTemplate详解 - 简书 (jianshu.com)
Swagger注释API :@ApiModel - Chen洋 - 博客园 (cnblogs.com)
导入swagger依赖:
1 | <dependency> |
1 | @ApiModel这个注解 |
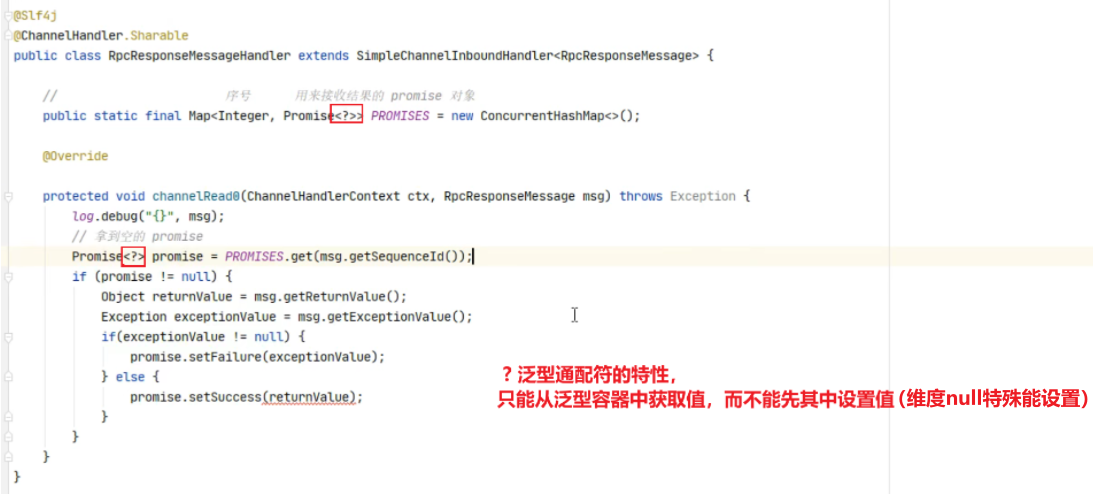
?泛型通配符的特性:只能从泛型容器种取值,而不能向其中设置值(唯独null特许地可以设置)