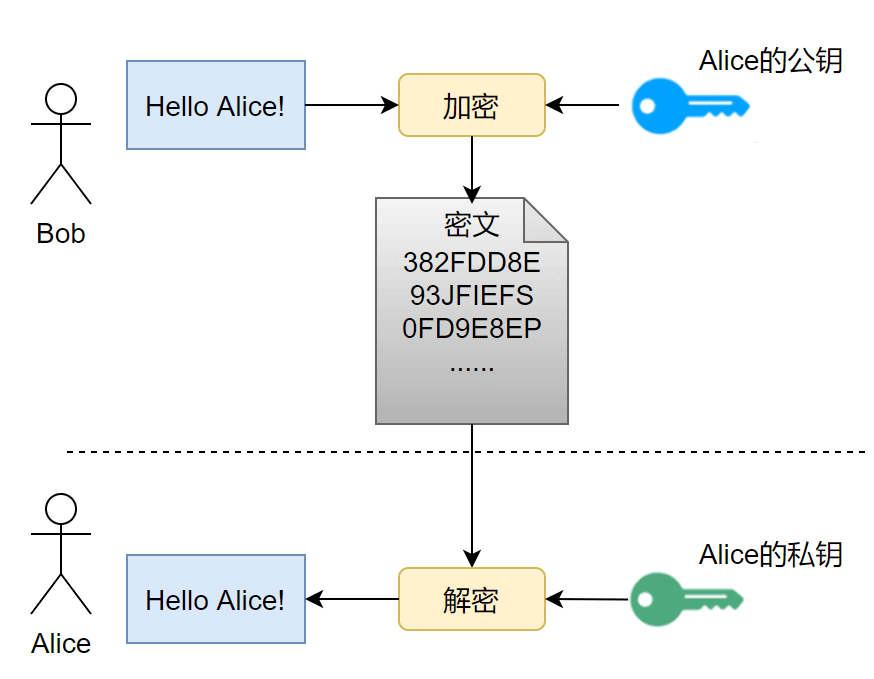
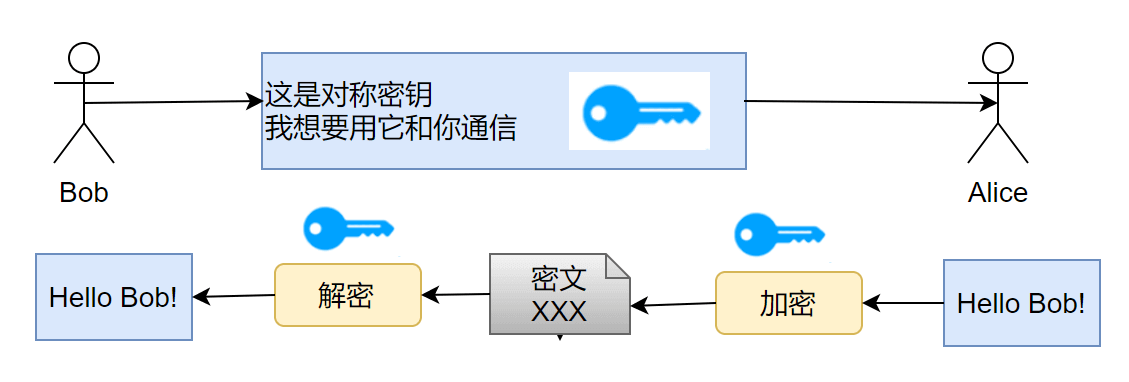
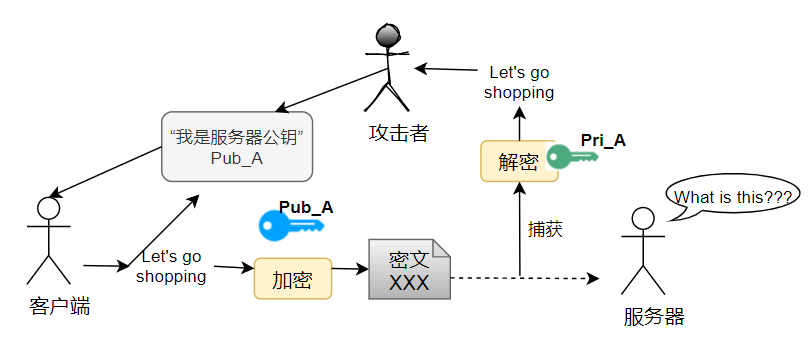
客户端 C 和服务器 S 想要使用 SSL/TLS 通信,由上述 SSL/TLS 通信原理,C 需要先知道 S 的公钥,而 S 公钥的唯一获取途径,就是把 S 公钥在网络信道中传输。要注意网络信道通信中有几个前提:
任何人都可以捕获通信包
通信包的保密性由发送者设计
保密算法设计方案默认为公开,而(解密)密钥默认是安全的
因此,假设 S 公钥不做加密,在信道中传输,那么很有可能存在一个攻击者 A,发送给 C 一个诈包,假装是 S 公钥,其实是诱饵服务器 AS 的公钥。当 C 收获了 AS 的公钥(却以为是 S 的公钥),C 后续就会使用 AS 公钥对数据进行加密,并在公开信道传输,那么 A 将捕获这些加密包,用 AS 的私钥解密,就截获了 C 本要给 S 发送的内容,而 C 和 S 二人全然不知。
同样的,S 公钥即使做加密,也难以避免这种信任性问题,C 被 AS 拐跑了!
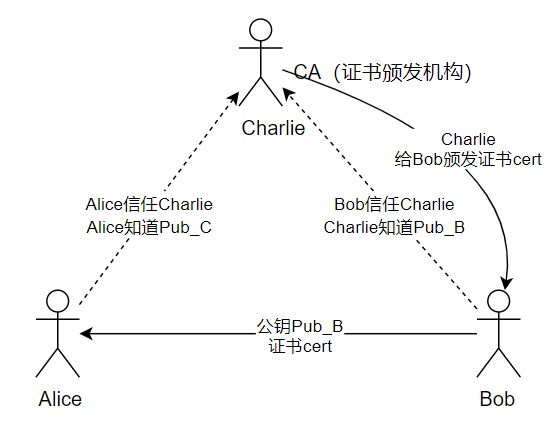
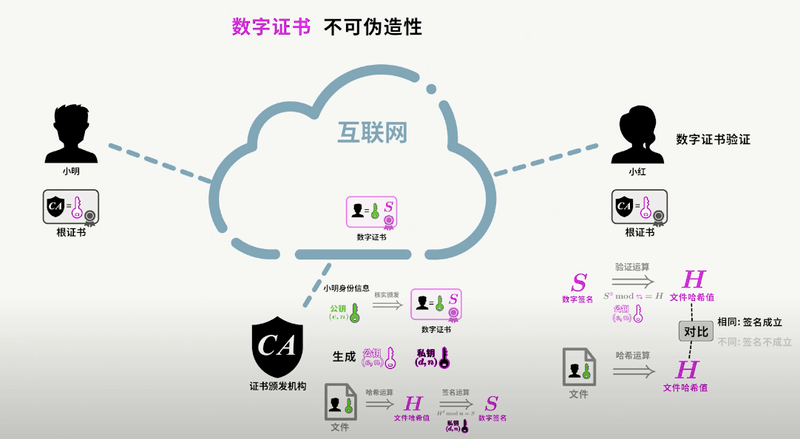
为了公钥传输的信赖性问题,第三方机构应运而生——证书颁发机构(CA,Certificate Authority)。CA 默认是受信任的第三方。CA 会给各个服务器颁发证书,证书存储在服务器上,并附有 CA 的电子签名(见下节)。
The server has fulfilled the request but does not need to return an entity-body, and might want to return updated metainformation. The response MAY include new or updated metainformation in the form of entity-headers, which if present SHOULD be associated with the requested variant.
If the client is a user agent, it SHOULD NOT change its document view from that which caused the request to be sent. This response is primarily intended to allow input for actions to take place without causing a change to the user agent’s active document view, although any new or updated metainformation SHOULD be applied to the document currently in the user agent’s active view.
The 204 response MUST NOT include a message-body, and thus is always terminated by the first empty line after the header fields.
MAC 地址的全称是 媒体访问控制地址(Media Access Control Address)。如果说,互联网中每一个资源都由 IP 地址唯一标识(IP 协议内容),那么一切网络设备都由 MAC 地址唯一标识。
可以理解为,MAC 地址是一个网络设备真正的身份证号,IP 地址只是一种不重复的定位方式(比如说住在某省某市某街道的张三,这种逻辑定位是 IP 地址,他的身份证号才是他的 MAC 地址),也可以理解为 MAC 地址是身份证号,IP 地址是邮政地址。MAC 地址也有一些别称,如 LAN 地址、物理地址、以太网地址等。
还有一点要知道的是,不仅仅是网络资源才有 IP 地址,网络设备也有 IP 地址,比如路由器。但从结构上说,路由器等网络设备的作用是组成一个网络,而且通常是内网,所以它们使用的 IP 地址通常是内网 IP,内网的设备在与内网以外的设备进行通信时,需要用到 NAT 协议。
MAC 地址的长度为 6 字节(48 比特),地址空间大小有 280 万亿之多(248),MAC 地址由 IEEE 统一管理与分配,理论上,一个网络设备中的网卡上的 MAC 地址是永久的。不同的网卡生产商从 IEEE 那里购买自己的 MAC 地址空间(MAC 的前 24 比特),也就是前 24 比特由 IEEE 统一管理,保证不会重复。而后 24 比特,由各家生产商自己管理,同样保证生产的两块网卡的 MAC 地址不会重复。
MAC 地址具有可携带性、永久性,身份证号永久地标识一个人的身份,不论他到哪里都不会改变。而 IP 地址不具有这些性质,当一台设备更换了网络,它的 IP 地址也就可能发生改变,也就是它在互联网中的定位发生了变化。
ARP 协议,全称 地址解析协议(Address Resolution Protocol),它解决的是网络层地址和链路层地址之间的转换问题。因为一个 IP 数据报在物理上传输的过程中,总是需要知道下一跳(物理上的下一个目的地)该去往何处,但 IP 地址属于逻辑地址,而 MAC 地址才是物理地址,ARP 协议解决了 IP 地址转 MAC 地址的一些问题。
在Java的早期设计中,允许把Integer[]数组赋值给Number[]变量,此时如果试图把一个Double对象保存到该Number[]数组中,编译可以通过,但在运行时抛出ArrayStoreException异常。这显然是一种不安全的设计,因此Java在泛型设计时进行了改进,它不再允许把 List 对象赋值给List 变量。
数组和泛型有所不同,假设Foo是Bar的一个子类型(子类或者子接口),那么Foo[]依然是Bar[]的子类型,但 G 不是 G 的子类型。Foo[]自动向上转型为Bar[]的方式被称为型变,也就是说,Java的数组支持型变,但Java集合并不支持型变。Java泛型的设计原则是,只要代码在编译时没有出现警告,就不会遇到运行时ClassCastException异常。
Java SE(J2SE,Java 2 Platform Standard Edition,标准版)
Java SE 以前称为 J2SE。它允许开发和部署在桌面、服务器、嵌入式环境和实时环境中使用的 Java 应用程序。Java SE 包含了支持 Java Web 服务开发的类,并为Java EE和Java ME提供基础。
Java EE(J2EE,Java 2 Platform Enterprise Edition,企业版)
Java EE 以前称为 J2EE。企业版本帮助开发和部署可移植、健壮、可伸缩且安全的服务器端Java 应用程序。Java EE 是在 Java SE 的基础上构建的,它提供 Web 服务、组件模型、管理和通信 API,可以用来实现企业级的面向服务体系结构(service-oriented architecture,SOA)和 Web2.0应用程序。2018年2月,Eclipse 宣布正式将 JavaEE 更名为 JakartaEE
Java ME(J2ME,Java 2 Platform Micro Edition,微型版)
Java ME 以前称为 J2ME。Java ME 为在移动设备和嵌入式设备(比如手机、PDA、电视机顶盒和打印机)上运行的应用程序提供一个健壮且灵活的环境。Java ME 包括灵活的用户界面、健壮的安全模型、许多内置的网络协议以及对可以动态下载的连网和离线应用程序的丰富支持。基于 Java ME 规范的应用程序只需编写一次,就可以用于许多设备,而且可以利用每个设备的本机功能。
3 Jdk和Jre和JVM的区别
看Java官方的图片,Jdk中包括了Jre,Jre中包括了JVM
JDK :Jdk还包括了一些Jre之外的东西 ,就是这些东西帮我们编译Java代码的, 还有就是监控Jvm的一些工具 Java Development Kit是提供给Java开发人员使用的,其中包含了Java的开发工具,也包括了JRE。所以安装了JDK,就无需再单独安装JRE了。其中的开发工具:编译工具(javac.exe),打包工具(jar.exe)等
JRE :Jre大部分都是 C 和 C++ 语言编写的,他是我们在编译java时所需要的基础的类库 Java Runtime Environment包括Java虚拟机和Java程序所需的核心类库等。核心类库主要是java.lang包:包含了运行Java程序必不可少的系统类,如基本数据类型、基本数学函数、字符串处理、线程、异常处理类等,系统缺省加载这个包
首先回顾一下在程序设计语言中有关将参数传递给方法(或函数)的一些专业术语。按值调用(call by value)表示方法接收的是调用者提供的值,而按引用调用(call by reference)表示方法接收的是调用者提供的变量地址。一个方法可以修改传递引用所对应的变量值,而不能修改传递值调用所对应的变量值。 它用来描述各种程序设计语言(不只是Java)中方法参数传递方式。
BIO (Blocking I/O): 同步阻塞I/O模式,数据的读取写入必须阻塞在一个线程内等待其完成。在活动连接数不是特别高(小于单机1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的 I/O 并且编程模型简单,也不用过多考虑系统的过载、限流等问题。线程池本身就是一个天然的漏斗,可以缓冲一些系统处理不了的连接或请求。但是,当面对十万甚至百万级连接的时候,传统的 BIO 模型是无能为力的。因此,我们需要一种更高效的 I/O 处理模型来应对更高的并发量。
String类中使用字符数组保存字符串,private final char value[],所以string对象是不可变的。StringBuilder与StringBuffer都继承自AbstractStringBuilder类,在AbstractStringBuilder中也是使用字符数组保存字符串,char[] value,这两种对象都是可变的。
privatevoidwriteObject(java.io.ObjectOutputStream s)throws java.io.IOException{ *// Write out element count, and any hidden stuff* intexpectedModCount= modCount; s.defaultWriteObject(); *// Write out array length* s.writeInt(elementData.length); *// Write out all elements in the proper order.* for (int i=0; i<size; i++) s.writeObject(elementData[i]); if (modCount != expectedModCount) { thrownewConcurrentModificationException(); }
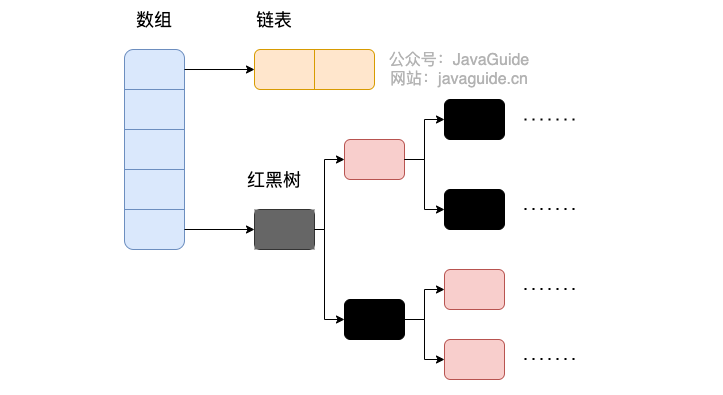
在JDK1.8中,放弃了Segment臃肿的设计,取而代之的是采用Node + CAS + Synchronized来保证并发安全进行实现,synchronized只锁定当前链表或红黑二叉树的首节点,这样只要hash不冲突,就不会产生并发,效率又提升N倍。
结构如下:
附加源码,有需要的可以看看
插入元素过程(建议去看看源码):
如果相应位置的Node还没有初始化,则调用CAS插入相应的数据;
1 2 3 4
elseif ((f = tabAt(tab, i = (n - 1) & hash)) == null) { if (casTabAt(tab, i, null, newNode<K,V>(hash, key, value, null))) break; // no lock when adding to empty bin }
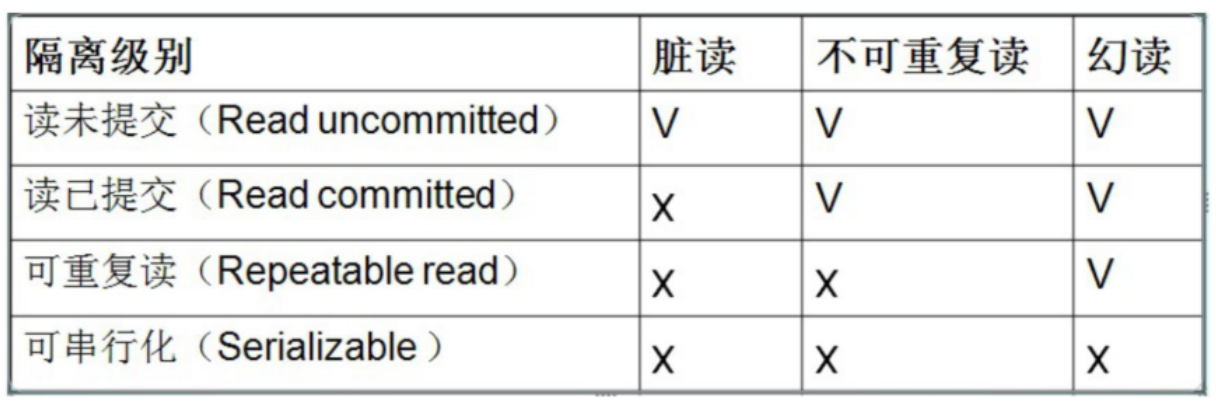
共享锁(Share Lock):S 锁,又称读锁(read lock),用于所有的只读数据操作。
S 锁并非独占,允许多个并发事务对同一资源加锁,但加 S 锁的同时不允许加 X 锁,即资源不能被修改。S 锁通常读取结束后立即释放,无需等待事务结束。
排他锁(Exclusive Lock):X 锁,又称写锁(write lock),表示对数据进行写操作。
X 锁仅允许一个事务对同一资源加锁,且直到事务结束才释放,其他任何事务必须等到 X 锁被释放才能对该页进行访问。使用 select * from table_name for update; 语句产生 X 锁。
更新锁:U 锁,用来预定要对资源施加 X 锁,允许其他事务读,但不允许再施加 U 锁或 X 锁。
当被读取的页将要被更新时,则升级为 X 锁,U 锁一直到事务结束时才能被释放。故 U 锁用来避免使用共享锁造成的死锁现象。
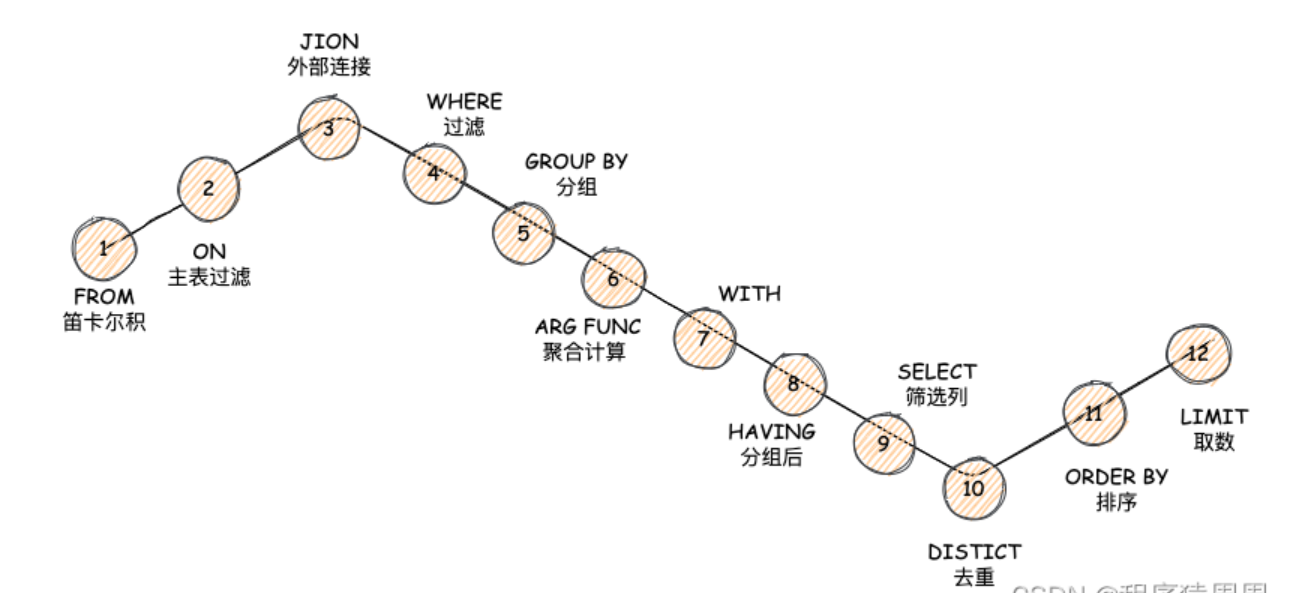
SELECT*FROM A,B(,C)或者SELECT*FROM A CROSSJOIN B (CROSSJOIN C) #没有任何关联条件,结果是笛卡尔积,结果集会很大,没有意义,很少使用内连接(INNERJOIN)SELECT*FROM A,B WHERE A.id=B.id或者SELECT*FROM A INNERJOIN B ON A.id=B.id多表中同时符合某种条件的数据记录的集合,INNERJOIN可以缩写为JOIN复制代码
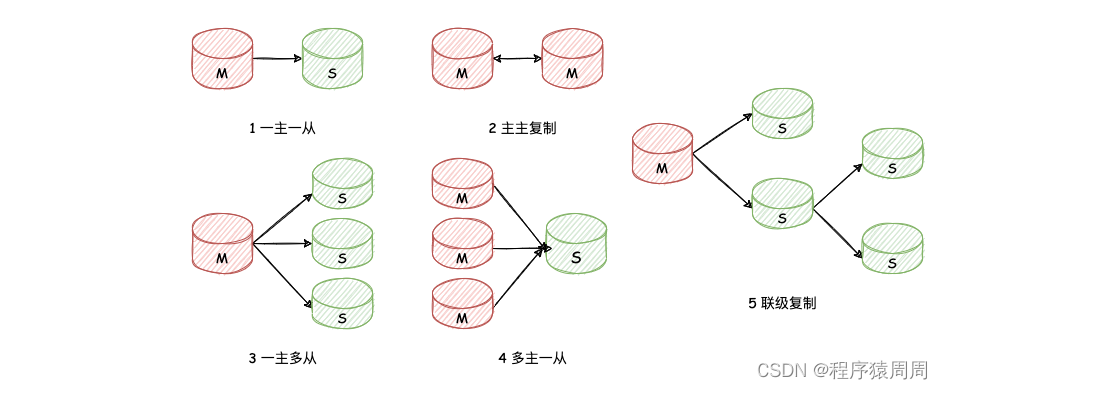
另外,在半同步复制时,如果主库的一个事务提交成功了,在推送到从库的过程当中,从库宕机了或网络故障,导致从库并没有接收到这个事务的Binlog,此时主库会等待一段时间(这个时间由rpl_semi_sync_master_timeout的毫秒数决定),如果这个时间过后还无法推送到从库,那 MySQL 会自动从半同步复制切换为异步复制,当从库恢复正常连接到主库后,主库又会自动切换回半同步复制。
数据库层面,这也是我们主要集中关注的(虽然收效没那么大),类似于select * from table where age > 20 limit 1000000,10这种查询其实也是有可以优化的余地的. 这条语句需要load1000000数据然后基本上全部丢弃,只取10条当然比较慢. 当时我们可以修改为select * from table where id in (select id from table where age > 20 limit 1000000,10).这样虽然也load了一百万的数据,但是由于索引覆盖,要查询的所有字段都在索引中,所以速度会很快. 同时如果ID连续的好,我们还可以select * from table where id > 1000000 limit 10,效率也是不错的,优化的可能性有许多种,但是核心思想都一样,就是减少load的数据.
Java程序中,许多对象在运行时都会有编译时异常和运行时异常两种,例如多态情况下Car c = new Audi(); 这行代码运行时会生成一个c变量,在编译时该变量的类型是Car,运行时该变量类型为Audi;另外还有更极端的情况,例如程序在运行时接收到了外部传入的一个对象,这个对象的编译时类型是Object,但程序又需要调用这个对象运行时类型的方法,这种情况下,有两种解决方法:第一种做法是假设在编译时和运行时都完全知道类型的具体信息,在这种情况下,可以先使用instanceof运算符进行判断,再利用强制类型转换将其转换成其运行时类型的变量。第二种做法是编译时根本无法预知该对象和类可能属于哪些类,程序只依靠运行时信息来发现该对象和类的真实信息,这就必须使用反射。 具体来说,通过反射机制,我们可以实现如下的操作:
java.util包下的集合类中,大部分都是非线程安全的,但也有少数的线程安全的集合类, 例如Vector、Hashtable,它们都是非常古老的API。虽然它们是线程安全的,但是性能很差,已经不推荐使用了。对于这个包下非线程安全的集合,可以利用Collections工具类,该工具类提供的synchronizedXxx()方法,可以将这些集合类包装成线程安全的集合类(如:List list = Collections.synchronizedList( new ArrayList<>() );),查看源码可知,其在所有的方法上加了synchronized修饰,从而达到同步的效果。